


들어가며
사내에서 DataHub를 메타데이터 관리 도구로 활용하고 있다. 입사 당시 버전이 0.13으로 낮았고, RDB 메타데이터만 ingestion되어 테이블과 컬럼 코멘트를 확인하는 정도로 사용하고 있었다.
이후 DataHub를 1.x 버전으로 업그레이드하고 Airflow와 dbt를 연동해 데이터 리니지를 확장했으며, Soda 기반 데이터 품질 검증 결과까지 DataHub에서 확인할 수 있도록 통합했다.
이 글에서는 다음 두가지 작업을 중심으로 정리해보려 한다.
•
리니지(Lineage)
Airflow와 dbt 메타데이터를 연동해 데이터가 어떤 소스에서 생성되어
어떤 테이블로 전달되는지 시각적으로 추적할 수 있도록 구성
•
품질 검증(Data Quality)
Soda로 수행한 데이터 품질 검증 결과를 DataHub Assertion으로 등록하여
테이블 단위로 검증 상태를 확인할 수 있도록 구현
리니지 연동
Airflow inlet/outlet
Airflow에서는 task 단위로 inlets와 outlets를 지정할 수 있다. 이 정보를 DataHub가 수집하여 데이터 리니지를 자동으로 구성한다.
즉 어떤 소스 테이블을 읽어 어떤 타겟 테이블을 생성하는지를 파이프라인 코드 레벨에서 명시적으로 정의하는 방식이다.
내부적으로는 두 가지 플러그인이 함께 동작한다.
•
acryl-datahub-airflow-plugin
◦
Airflow DAG/Task 메타데이터와 inlet/outlet 정보를 DataHub로 전송하는 역할
◦
datahub_rest_default 커넥션을 통해 DataHub REST API로 전송
•
openlineage-airflow
◦
OpenLineage 표준 스펙으로 리니지 이벤트를 생성하는 역할
◦
datahub-airflow-plugin이 이 이벤트를 받아서 DataHub 메타데이터 포맷으로 변환해 전송
즉, Airflow Task 실행 → OpenLineage 이벤트 생성 → datahub-airflow-plugin → DataHub REST API 의 흐름
예시 코드
from datahub_airflow_plugin.entities import Dataset
@task(
inlets=[
Dataset("mysql", "db.source_table_a"),
Dataset("mysql", "db.source_table_b"),
],
outlets=[
Dataset("athena", "db.result_table"),
],
)
def process():
...
Python
복사
•
위 설정을 통해 MySQL의 두 테이블을 읽어 처리한 뒤 Athena의 결과 테이블로 적재된다는 흐름을 DataHub가 인식할 수 있다.
•
Task가 실행될 때마다 이 inlet/outlet 정보가 DataHub로 전송되어 데이터 리니지가 지속적으로 갱신된다.
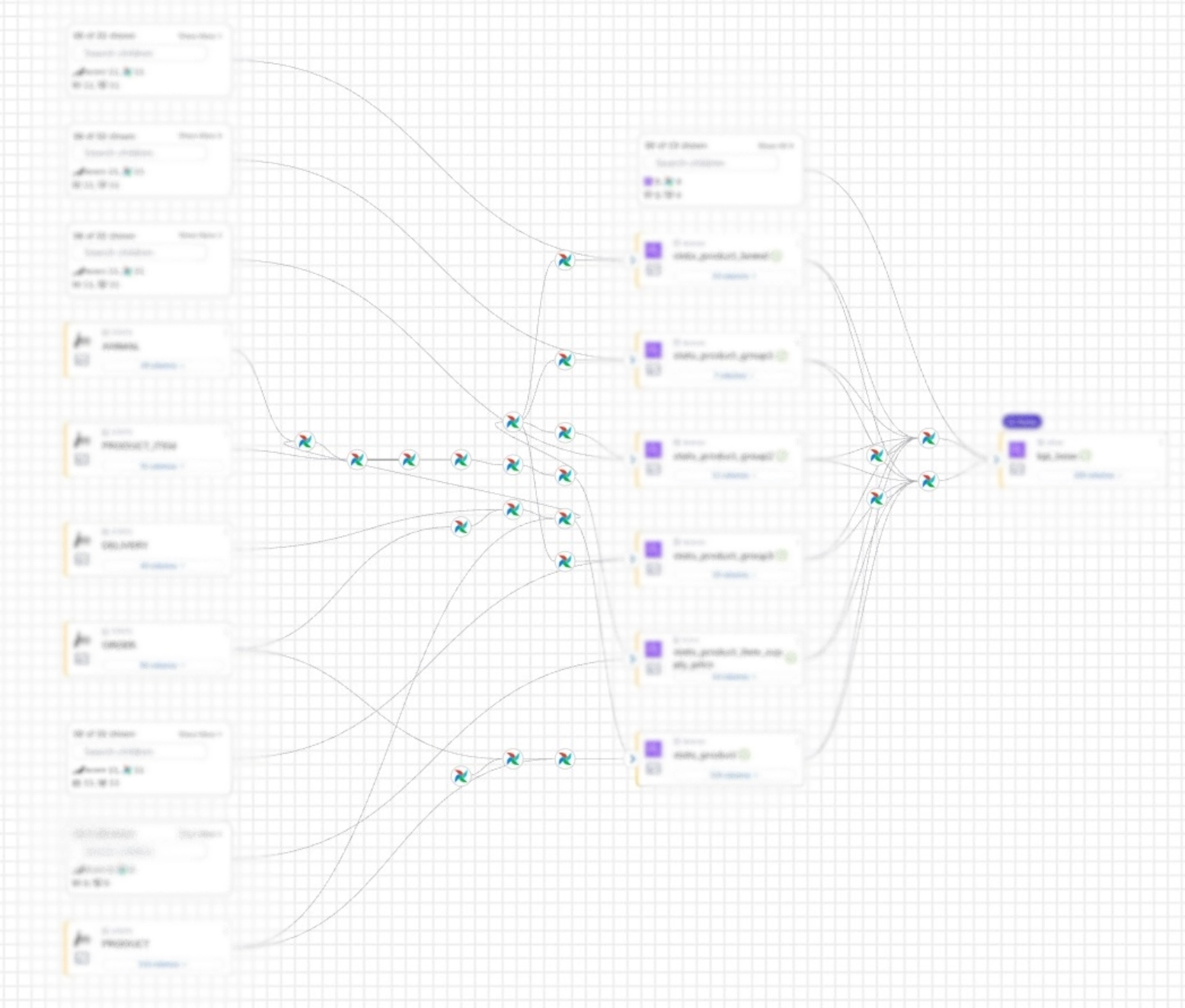
kpi 집계의 전체 흐름 확인 예시
dbt docs 연동
dbt는 프로젝트 구조를 문서화할 수 있는 기능을 제공한다. dbt docs generate 명령어를 실행하면 dbt 모델 정의, 컬럼 설명, 모델 간 의존관계를 정리한 문서 아티팩트가 생성된다.
이 아티팩트를 이용하면 dbt 프로젝트의 데이터 흐름을 UI에서 시각적으로 확인할 수 있다.
dbt docs generate 를 실행하면 여러 아티팩트가 생성되는데, DataHub 연동에는 다음 두 파일이 사용된다.
•
manifest.json
◦
dbt 프로젝트의 모델 구조와 의존관계를 담고 있는 파일
◦
어떤 모델이 어떤 upstream 모델을 참조하는지 등의 lineage 정보 포함
•
catalog.json
◦
실제 데이터베이스에 생성된 테이블의 컬럼 정보와 타입, row count 등 메타데이터 담고 있는 파일
DataHub ingestion이 이 두 파일을 읽어 dbt 모델 메타데이터와 lineage 정보를 DataHub에 등록한다.
또한 앞서 Airflow에서 수집한 리니지와 연결되기 때문에 파이프라인 → dbt 모델 → 결과 테이블까지전체 데이터 흐름을 하나의 그래프로 확인할 수 있다.
DataHub에 dbt 메타데이터를 수집하기 위해 다음 과정을 구성했다.
1.
아티팩트 생성 및 S3 업로드
매일 새벽에 Airflow DAG이 dbt docs generate를 실행하고 결과물을 S3에 업로드
2.
DataHub ingestion 레시피
DataHub 소스 레시피에서 S3 경로를 바라보도록 설정해 dbt 메타데이터 수집
source:
type: "dbt"
config:
manifest_path: "${DBT_MANIFEST_PATH}"
catalog_path: "${DBT_CATALOG_PATH}"
target_platform: "athena"
aws_connection:
aws_region: ap-northeast-2
sink:
type: "datahub-rest"
config:
server: "http://datahub-gms:8080"
transformers:
- type: "simple_add_dataset_tags"
config:
tag_urns:
- "urn:li:tag:dbt"
YAML
복사
이렇게 dbt 메타데이터를 DataHub에 수집하면 dbt 모델 간 의존관계와 데이터 리니지를 UI에서 확인할 수 있다.
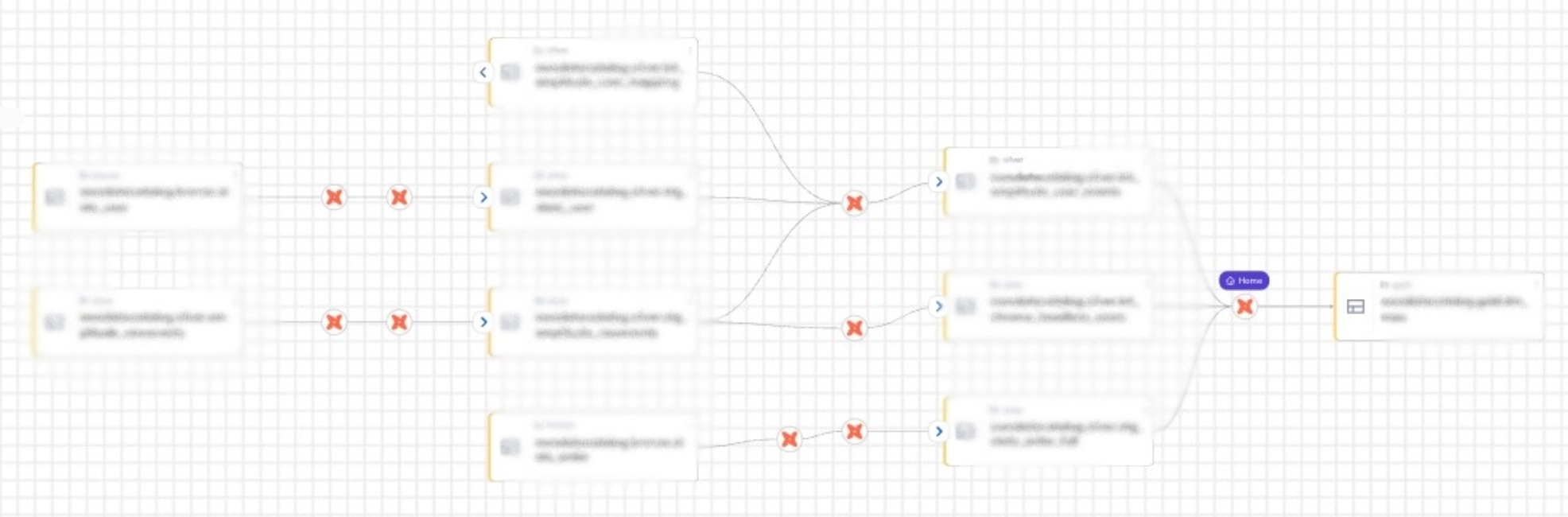
dbt 모델 리니지
품질검증 연동
Soda 체크
Soda는 YAML 파일로 데이터 품질 검증을 정의하고 실행하는 오픈소스 Data Quality 도구이다. SQL을 직접 작성하지 않아도 row_count, missing_count, duplicate_count 같은 검증을 선언형으로 관리할 수 있다.
검증 항목들은 yaml 파일로 관리한다. 단순 null/중복 체크부터 전일 대비 급감 탐지, 비즈니스 플래그 로직 검증 등 다양한 규칙을 정의 할 수 있다.
filter orders [daily]:
where: created_at >= '${year}-${month}-${day} 00:00:00'
checks for orders [daily]:
# 기본 검증
- row_count > 0
- missing_count(order_id) = 0
- duplicate_count(order_id) = 0
# 비즈니스 로직 검증
- failed rows:
name: zero_or_negative_quantity
fail condition: 'quantity <= 0'
# 전일 대비 급감 탐지
- row_count_ratio > 0.5:
row_count_ratio query: |
SELECT
CAST(SUM(CASE WHEN day='${day}' THEN 1 ELSE 0 END) AS DOUBLE)
/ NULLIF(SUM(CASE WHEN day='${prev_day}' THEN 1 ELSE 0 END), 0)
FROM orders
YAML
복사
모든 수집 테이블에는 기본적으로 source freshness 검증을 설정했다.
또한 각 수집 파이프라인의 마지막 task에서 Soda scan을 실행하도록 구성해 파이프라인이 완료되면 자동으로 데이터 품질 검증이 수행되도록 했다.
DataHub API 전송
현재 Soda는 DataHub와 공식적인 통합을 제공하지 않는다. 따라서 Soda에서 생성된 체크 결과를 DataHub 메타데이터 모델로 변환해 직접 전송하는 방식을 택했다.
Soda 체크 결과를 DataHub의 Assertion 모델로 변환한 뒤 DatahubRestEmitter를 사용해 DataHub API로 전송하도록 구현했다.
다음 코드는 Soda 검증 결과를 DataHub Assertion으로 등록하는 예시이다.
from datahub.emitter.rest_emitter import DatahubRestEmitter
from datahub.metadata.schema_classes import (
AssertionInfoClass,
AssertionRunEventClass,
AssertionResultTypeClass,
)
emitter = DatahubRestEmitter(gms_server="http://datahub-gms:8080")
# 1. AssertionInfo: check 정의 upsert
emitter.emit(
MetadataChangeProposalWrapper(
entityUrn=assertion_urn,
aspect=AssertionInfoClass(
type=AssertionTypeClass.DATASET,
datasetAssertion=DatasetAssertionInfoClass(
dataset=dataset_urn,
nativeType=check_name,
),
description=f"[{pipeline_name}] {check_name}",
),
)
)
# 2. AssertionRunEvent: 실행 결과 emit
emitter.emit(
MetadataChangeProposalWrapper(
entityUrn=assertion_urn,
aspect=AssertionRunEventClass(
timestampMillis=now_ms,
result=AssertionResultClass(
type=AssertionResultTypeClass.SUCCESS # or FAILURE
),
status=AssertionRunStatusClass.COMPLETE,
),
)
)
Python
복사
검증이 성공적으로 완료되면 DataHub UI에서 해당 테이블 이름 옆에 체크 표시가 나타난다. 이를 통해 해당 데이터셋이 품질 검증을 통과했는지 한 눈에 확인할 수 있다.
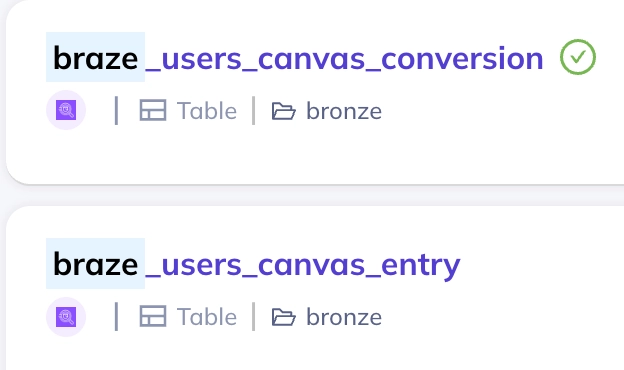
체크 표시 유/무
또한 테이블 상세 화면에서 실행된 품질 검증 목록과 각 검증의 성공/실패 여부를 확인할 수 있다.
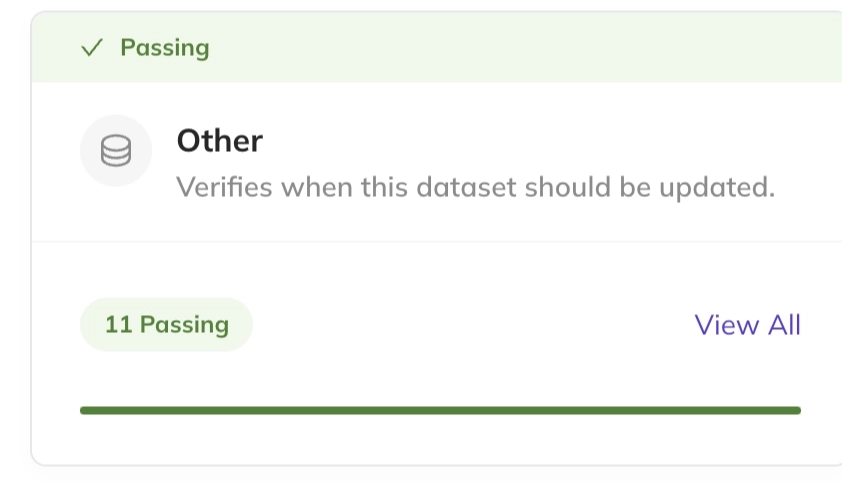
11개의 테스트 통과
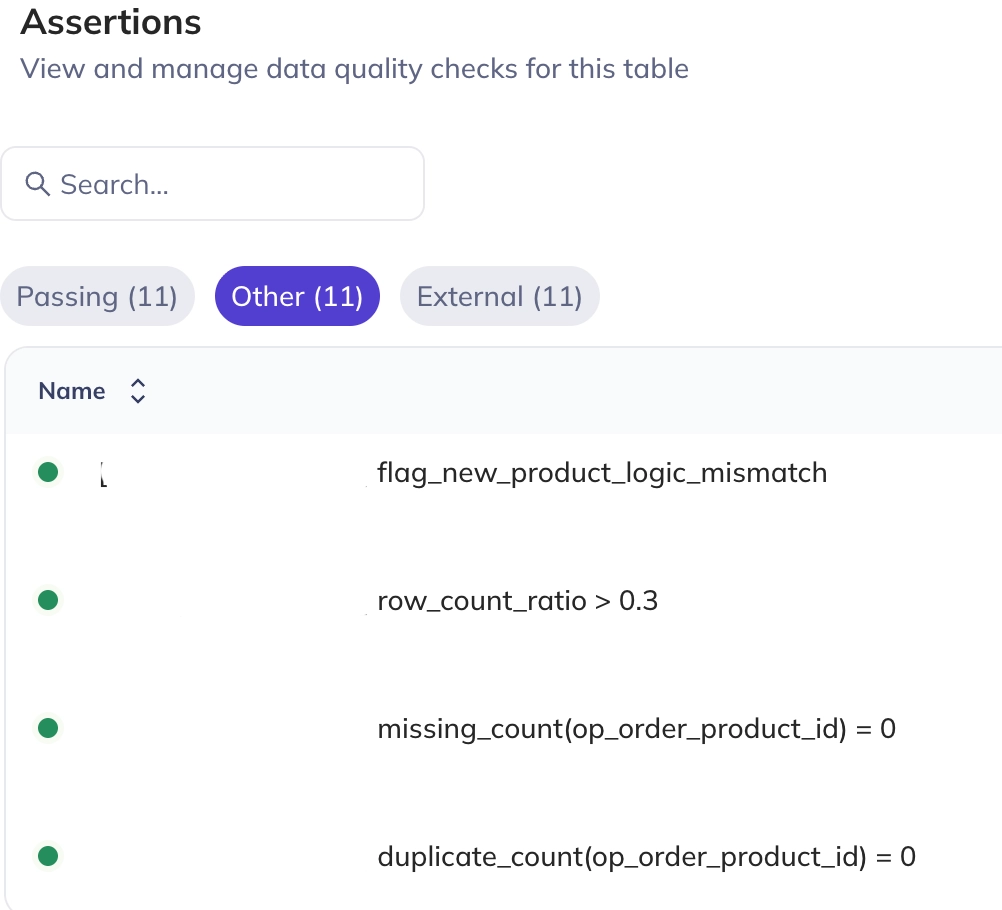
상세 검증 목록 확인
실제 활용 사례
분석가 온보딩
새로 합류한 분석가에게 DataHub를 공유했더니, 테이블 간 리니지를 보면서 데이터 흐름을 빠르게 파악할 수 있었다고 했다.
분석가는 Airflow 파이프라인을 직접 관리하지 않기 때문에 DAG 코드를 열어 데이터 흐름을 확인하기 어려웠다.
이제는 DataHub에서 리니지를 통해 어떤 테이블이 어떤 파이프라인을 거쳐 생성되는지 확인할 수 있다.
데이터 출처 추적
특정 데이터가 어느 파이프라인에서 수집되는지 찾아야 할 때가 있다.
이전에는 Airflow DAG 코드와 스크립트를 직접 검색해야 했지만, 이제는 DataHub에서 메타데이터와 리니지를 따라 올라가며 데이터 수집 경로를 쉽게 확인할 수 있다.
마치며
DataHub를 단순 메타데이터 조회 도구에서 리니지와 품질검증까지 통합하는 작업을 진행했다. Airflow inlet/outlet과 dbt docs 연동으로 파이프라인 전체 흐름이 한 화면에서 보이게 됐고, Soda 검증 결과까지 붙으니 테이블 하나를 열었을 때 "어디서 왔고, 잘 들어오고 있는지"를 한번에 파악할 수 있게 됐다.
잘 정리된 메타데이터는 AI 활용의 기반이 되기도 한다. DataHub가 MCP 서버를 공식 지원하는 만큼, 이를 활용해 자연어로 영향도를 조회하거나 테이블 스키마 기반 Text-to-SQL 같은 시도도 해볼 예정이다.
메타데이터를 잘 쌓아둘수록 이런 활용의 품질도 올라간다는 점에서, 지금 하고 있는 작업이 단순한 문서화 이상의 의미를 가진다고 생각한다.