

All







3장에서 다루는 내용
•
6계층 데이터 플랫폼 아키텍처 설계
•
배치와 스트리밍 데이터 모두 지원하는 계층 구축 방법
•
AWS 클라우드 데이터 플랫폼
6계층 데이터 플랫폼 아키텍처
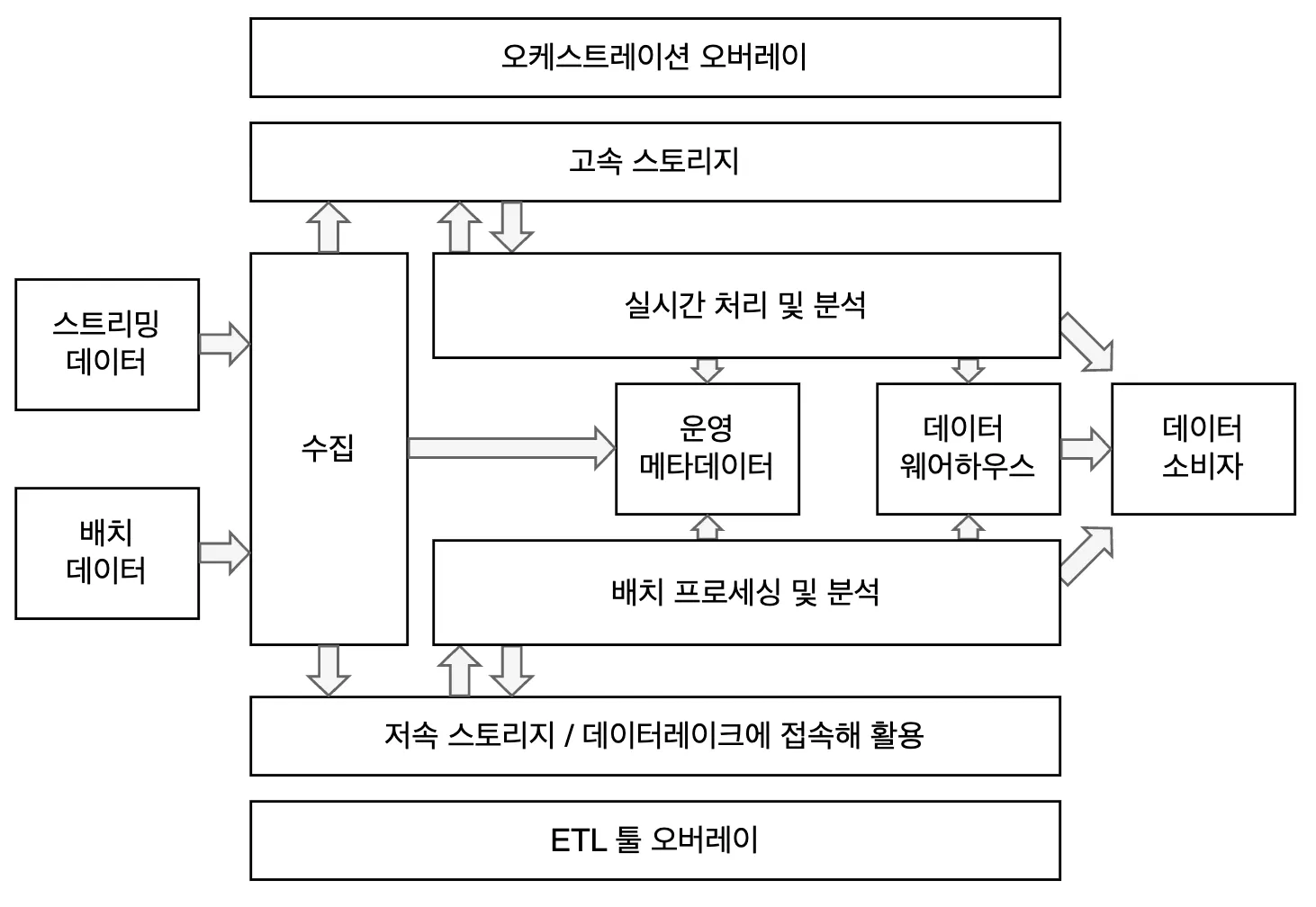
1. 데이터 수집 계층
소스 시스템에서 원시(raw) 데이터를 플랫폼으로 가져옴
•
스트리밍, 배치모드에서 다양한 데이터 소스로 연결
◦
스트리밍 - 한 번에 하나의 이벤트 데이터에 액세스
◦
배치 - CSV, JSON 파일을 수집하는 FTP 서버나 배치 액세스만 제공하는 세스템 수집
•
데이터 변환을 크게 거치지 않고 원시 데이터 전송
•
커넥터 추가만으로 새로운 소스 지원 가능한 플러그형 설계
•
메타데이터 저장소에 수집 통계와 수집 상태 등록
◦
스트리밍 - 특정 시간 간격동안 데이터 수집량
◦
배치 - 배치당 데이터 수집량
2. 고속 스토리지와 저속 스토리지
저속/고속이란 HDD나 SDD 드라이브 같은 특정 하드웨어 특성이 아닌, 유스케이스에 따른 스토리지 소프트웨어 설계 특성을 말함
저속 스토리지
•
배치 데이터 보존용 영구 저장소
•
클라우드 객체 저장소(S3, GCS 등) 활용 - 연결된 컴퓨팅 서버 없어서 저장소 용량 확장/축소가 용이
•
짧은 지연 액세스 지원하지 않음
고속 스토리지
•
단일 메시지의 읽기/쓰기 작업시 짧은 지연 액세스 가능(kafka)
•
스트림 방식 데이터를 각 메시지 단위로 처리하기 위한 메시지 버스
•
TTL 만료 정책으로 최신 데이터 유지
•
컴퓨팅 노드 필요 → 비용 상승
3. 처리 계층
비즈니스 로직 적용, 데이터 검증 및 변환 수행
•
스토리지 배치 방식이나 스트리밍 처리 방식으로 데이터 읽고 비즈니스 로직 적용
•
변환 결과를 다시 스토리지에 저장하여 분석가·데이터 과학자에 제공
•
스케일 아웃 시킬수 있는 구조로 큰 데이터 규모를 효율적으로 처리
•
프로그래밍 언어 지원
4. 기술 메타데이터 계층
•
기술 메타데이터
◦
데이터 소스의 스키마 정보
◦
파이프라인 상태(성공, 실패) 및 통계(처리량, 지연)
◦
데이터 계보 (lineage)
•
메타데이터 계층은 데이터 플랫폼의 중심으로 메타데이터 저장소에 보관
•
완벽한 기능을 갖춘 솔루션이 없음
◦
컨플루언트 스키마 레지스트리, Glue Data Catalog 등 다양한 툴 섞어 사용
5. 서비스 계층과 데이터 소비자
다양한 데이터 소비자에게 분석 결과물 제공하는 역할
•
데이터 소비자 - 스트림 직접 소비를 원하거나 원시 데이터 원하거나 구조화된 데이터 원할 수도 있음
•
데이터 웨어하우스는 구조화된 데이터 셋 관리하는 영역으로 서비스 계층에 거의 포함
•
애플리케이션도 데이터 소비자
◦
실시간 추천, 광고입찰 등 실시간 분석 결과물은 사람보다 애플리케이션이 소비
◦
주로 전용 API 사용하며 별도 API 계층 필요한 경우도 있음
6. 오케스트레이션 오버레이와 ETL 오버레이 계층
오케스트레이션 계층
데이터 처리 작업 간의 의존성을 조정하고, 실패 시 재시도를 관리하는 계층
•
DAG(Directed Acyclic Graph) 기반으로 여러 워크플로우를 제어
•
작업 간의 순서를 명확하게 정의하고, 오류 발생 시 재시도 로직 수행
•
수백~수천 개의 작업 의존성을 효율적으로 관리 가능
•
주로 Apache Airflow 사용
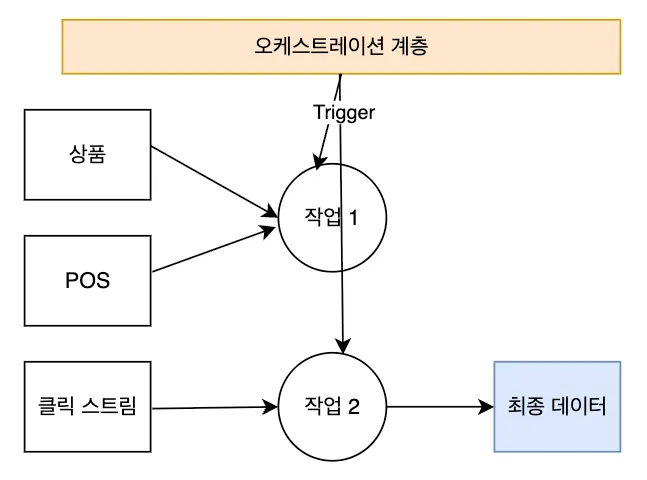
시나리오 예시 - 온/오프라인 데이터 통합 분석
•
온/오프라인에서 가장 많이 팔리는 제품 비교
1.
ERP 시스템에서 제품 정보 데이터 가져옴
2.
POS 시스템에서 오프라인 판매 데이터 수집
3.
온라인 몰 클릭스트림 데이터는 실시간 스트리밍으로 수집
•
작업 1 - 제품 정보과 POS 판매 데이터 결합
•
작업 2 - 클릭 스트림데이터와 작업 1결과 결합해 비교 세트 생성
→ 작업 2는 작업 1의 결과를 필요로 하므로, 작업 간 의존성 존재
오케스트레이션 계층은 이러한 관계를 인지하고 순차적 실행 및 오류 처리를 관리
ETL 오버레이 계층
데이터 파이프라인을 쉽게 구현하고 유지 관리하도록 돕는 계층
•
다양한 소스에서 들어오는 데이터 수집을 추가하고 구성(수집계층)
•
데이터 처리 파이프라인 생성(처리계층)
•
파이프라인에 대한 메타데이터 저장(메타데이터 계층)
•
다양한 작업 조율(오케스트레이션 계층)
→ 거의 모든 계층에 활용 가능
대표 예시 - AWS Glue, Talend, Informatica, dbt 등
장점
•
GUI 또는 선언형 방식으로 파이프라인 구현이 간편
•
코드 작성 없이도 빠른 PoC와 초기 설계 가능
한계점
•
플랫폼 규모가 커질수록 정형화된 ETL 서비스만으로는 요구사항을 충족하기 어려움
•
점차 커스텀 처리나 외부 시스템 연동 등을 위해 별도 구현이 늘어나며, 초기 솔루션 자체만큼 복잡한 구조로 진화할 수 있음
•
확장성·유지보수 관점에서 스파게티 아키텍처로 변질되지 않도록 주의 필요
계층 분리의 중요성
•
데이터 플랫폼 아키텍처 계층은 최대한 분리 (느슨한 결합)
•
각 계층간 잘 정의된 인터페이스로 통신
•
유연성이 좋아야 필요한 서비스나 툴의 선택폭이 대폭 늘어남
•
클라우드 서비스는 지속적인 변화가 있기 때문에, 느슨하게 결합으로 전체 플랫폼에 미치는 영향 최소화하면서 변화에 대응가능
각 계층에 활용할 수 있는 도구
데이터 플랫폼 아키텍처를 구성할 때, 각 계층별로 사용할 수 있는 도구는 다양하며 아키텍처의 유연성·확장성·운영 난이도에 따라 선택이 달라짐
도구 유형별 비교
•
완전 관리 솔루션
◦
서버 관리, 라이브러리 버전 관리 등 운영 부담 적음
◦
기능 제약이 많아 확장성 제일 떨어짐
•
서버리스 솔루션
◦
서버 관리하거나 확장성 내결함성 걱정할 필요 없어 간단하고 빠르게 구현할때 좋음
◦
코드를 직접 작성할 수 있기에 유연성이 더 높음
◦
복잡한 처리는 불가
•
오픈 소스
◦
유연성 이동성이 뛰어나지만
◦
VM 프로비저닝, 모니터링, 유지보수 작업 공수가 훨씬 크다
AWS 기반 예시
계층 | AWS 서비스 예시 |
수집 | Kinesis, DMS, Lambda, Glue |
고속 스토리지 | Kinesis |
저속 스토리지 | S3, Athena |
오케스트레이션 & 운영 메타데이터 | Glue, Step Functions, Data Catalog |
배치 처리 & 분석 | EMR, Glue Studio |
데이터 웨어하우스 | Redshift |
실무에서 많이 사용하는 조합
계층 | 서비스 |
수집 | Apache Kafka, AWS Lambda, DMS, Python 스크립트 + Airflow 조합 |
고속 스토리지 | Apache Kafka |
저속 스토리지 | Amazon S3, Athena |
오케스트레이션 | Apache Airflow |
ETL 도구 | dbt, Glue |
운영 메타데이터 | Glue Data Catalog |
배치/스트리밍 처리 | EMR (Spark), Kafka Streams, Apache Flink |
데이터 웨어하우스 | BigQuery, Redshift |