

All







7.1 메타데이터의 의미
메타데이터(Metadata): 다른 데이터에 대한 정보를 제공하고 설명하는 “데이터에 대한 데이터”의 집합
— 데이터 자체에 포함되지 않으므로 별도로 수집·관리해야 검색·분류·추적이 용이
7.1.1 비즈니스 메타데이터
•
데이터 소비자(분석가·BI 사용자)를 위한 설명 정보
•
주요 항목 - 데이터의 출처, 소유자, 생성일자, 파일크기, 용도 등
◦
예: 2024년 5월 생성된 고객 주문 데이터, CRM 팀 소유, S3에 저장됨
•
관련 서비스 - AWS Glue Data Catalog
7.1.2 파이프라인 메타데이터(데이터 플랫폼 내부 메타데이터)
•
데이터 플랫폼 내부에서 파이프라인 동작·상태를 설명하는 메타데이터
•
파이프라인 설명, 데이터 소스·데스티네이션 정보, 실행 시점(성공/실패), 에러 원인, 실행 통계 등
•
자동화, 모니터링, 설정관리 시 필수 요소
7.2 파이프라인 메타데이터 장점
복잡해지는 처리과정을 효과적으로 관리하기 위해 코드 구현 영역과 외부 설정값(메타데이터) 분리해야 함
문제점: 코드 기반 관리
1.
기능 추가 방식
•
단일 파이프라인에 모든 로직을 집어넣으면 유지보수 어려움
2.
파이프라인 복제 방식
•
코드 중복, 변경 시 전 파이프라인 동시 수정 필요
>> 해결책: 설정 방식의 파이프라인 설계
•
동일 코드, 다른 설정: 유사한 구조의 데이터 소스 처리를 하나의 코드로 관리
•
설정값 추상화: 데이터 소스 이름과 소스 시스템 관련 정보는 설정값 형태로
•
코드 수정 없이 설정값만 업데이트하여 신규 파이프라인 추가 가능
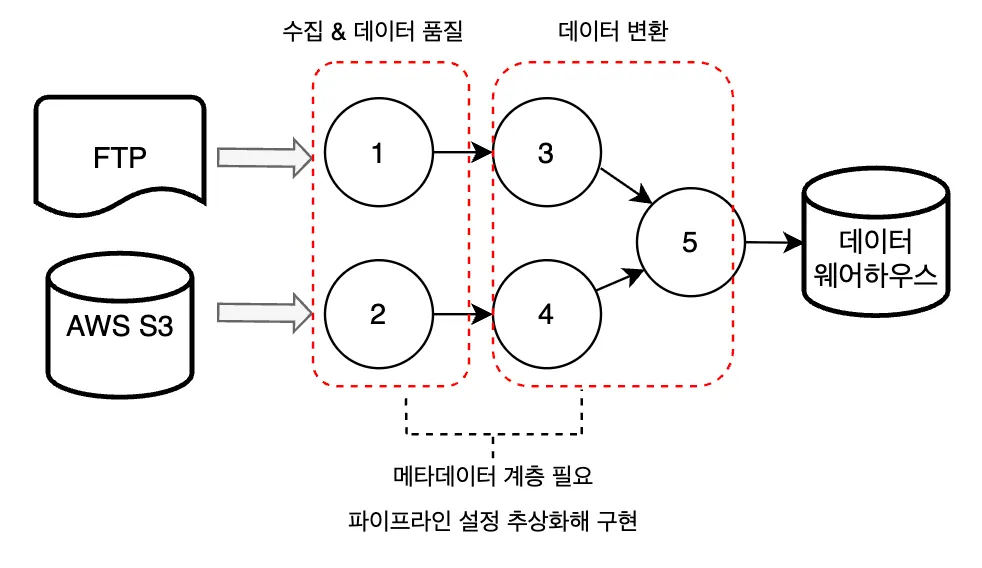
메타데이터의 세가지 기능
•
중앙 설정 저장소
◦
모든 파이프라인 구성 정보를 중앙에서 관리
•
파이프라인 실행 이력 및 모니터링
◦
성공/실패 여부, 실행 시간, 처리량 등 운영 데이터 수집
•
스키마 저장소
◦
각 데이터셋의 컬럼 정보, 타입, 변경 이력 등 추적
메타데이터 계층은 데이터 엔지니어와 데이터 사용자의 기본 인터페이스가 되어야 함
7.3 메타데이터 모델
•
메타데이터 모델의 문제는 업계 표준이 없다는 것으로 책에서는 보편적인 모델 소개함
•
이를 참고해 조직 요구사항에 맞게 모델 확장 할 것
7.3.1 메타데이터 도메인
•
메타데이터 항목은 아래 그림과 같이 네 가지 도메인으로 분리
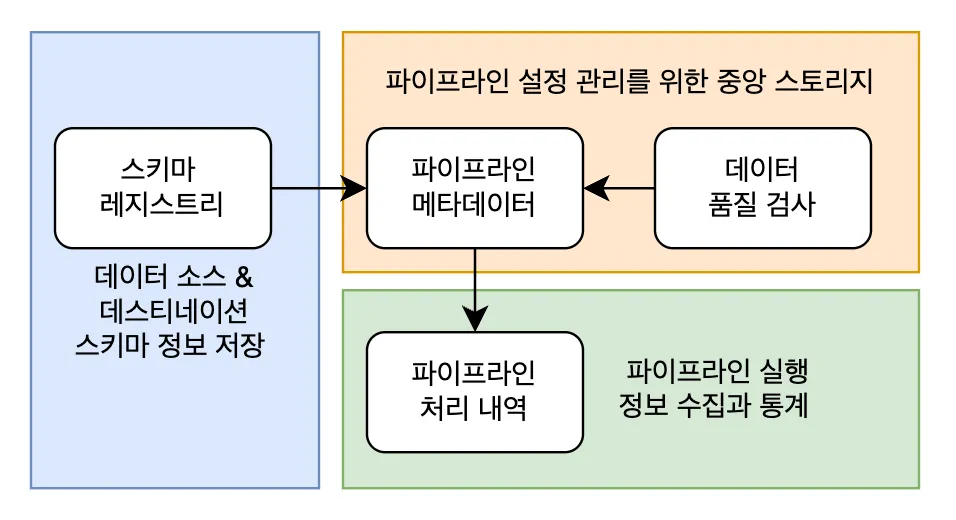
주요 메타데이터 도메인과 각 도메인 간의 관계
파이프라인 메타데이터
파이프라인의 정의와 구성을 담고 있는 메타데이터
각 컴포넌트와 속성
•
네임스페이스 (Namespace)
◦
최상위 그룹 단위
◦
속성
▪
namespace_id: 고유 식별자
▪
name: 네임스페이스 이름
▪
description: 설명
▪
created_at / updated_at: 생성·수정 시각
•
파이프라인 정의 (Pipeline Definition)
◦
수집·변환 작업의 논리적 단위
◦
속성
▪
pipeline_id: 고유 식별자
▪
name / description: 이름과 설명
▪
type: 실시간(stream) / 배치(batch)
▪
source_target_map: 소스 ⇔ 데스티네이션 매핑 정보
▪
quality_check_id: 연계된 데이터 품질 검사 참조
▪
connect_info: 연결 세부 정보 (예: JDBC URL, Kafka 호스트/IP, FTP 경로)
▪
created_at / updated_at
•
데이터 소스 & 데스티네이션 (Data Source & Destination)
◦
파이프라인이 읽거나 쓰는 엔티티
◦
속성
▪
entity_id: 고유 식별자
▪
name: 이름
▪
schema_id: 스키마 레지스트리 참조
▪
quality_check_id: 품질 검사 참조
▪
type: RDB, 파일, 메시지 큐 등
▪
created_at / updated_at
•
데이터 품질 규칙 (Data Quality Rules)
◦
파이프라인에서 적용할 품질 검사 정의
◦
속성
▪
rule_id: 고유 식별자
▪
name: 규칙 이름
▪
severity: 영향도 수준 (예: INFO, WARNING, CRITICAL)
▪
definition: 검사 조건 및 쿼리
▪
created_at / updated_at
파이프라인 처리 내역
실제 실행 중 수집되는 운영 통계와 상태 정보
•
파이프라인 실행시 지속적으로 수집되며 운영시 발생하는 다양한 문제들의 트러블슈팅시 유용
•
배치의 경우 시작과 종료 시간이 명확하지만, 실시간은 그렇지 않으므로 고정 주기로 통계 수집
•
모니터링 연계 - 특정 지표가 비정상적으로 작동할때 관련 경고 보내도록 구성 가능
주요 속성
•
execution_id: 실행 고유 식별자
•
pipeline_id: 연계된 파이프라인
•
start_time / end_time: 시작·종료 시각
•
status: SUCCESS / FAILED / RUNNING 등
•
error_message: 오류 상세(실패 시)
•
read_count / write_count: 처리된 행 수
•
read_bytes / write_bytes: 처리된 바이트 크기
•
extra: 데이터 저장 경로, 토픽 위치정보, 실시간 주기 등
데이터 품질 검사
•
수집/변환 파이프라인에 적용되는 품질 검사 정보
검사 유형 예시
•
누락 값 비율
•
중복 레코드 검사
•
컬럼별 값 범위 검증
스키자 레지스트리
•
데이터 소스·데스티네이션의 스키마(컬럼, 타입, 제약조건 등)를 관리
핵심 기능
•
버전 관리: 변경 이력 추적
•
호환성 정책: 전·후방 호환성 설정
•
API 제공: 스키마 조회·등록
7.4 메타데이터 계층 구현
•
메타데이터 계층은 업계 표준 소스나 상용 솔루션이 없음 → 직접 구현 하면서 데이터 플랫폼과 조직 규모에 따라 단계별 확장 권장
7.4.1 설정 파일 방식
•
가장 간단한 구현방법
•
장점: 단순·저비용, 소규모 플랫폼에 적합
•
단점: 설정 파일 수 증가 시 검색·관리 어려움
•
파이프라인 메타데이터
◦
JSON/YAML 같은 포맷으로 관리
◦
버전관리 - Git으로 설정 변경 이력 추적 가능
◦
자동화 - CI/CD로 설정 파일을 클라우드 스토리지에 복사
•
처리내역 메타데이터
◦
정적이지 않기 때문에 처리내역과 로그들을 계속해서 저장
◦
로그는 툴없이 분석 어려움. 구조화된 로깅 필요
◦
AWS 엘라스틱서치 제공
7.4.2 메타데이터 데이터베이스
•
설정 파일 방식이 파일이 많아질수록 설정값 찾기 어려운 문제를 데이터베이스 사용으로 해결
•
구조가 계속 변경되기 때문에 관계형보다 도큐먼트 저장소가 더 적합
•
쿼리로 검색 가능하기 때문에 대용량 관리에 용이함
7.4.2 메타데이터 API
•
조직 규모가 커지면 여러 팀에서 하나의 데이터베이스를 두고 작업하기 어려워짐 (영향도 문제)
•
규모가 큰 데이터 플랫폼은 API 계층을 도입해 API로만 메타데이터 조작
7.5 기존 솔루션
7.5.1 클라우드
AWS Glue
•
기능
◦
데이터 소스·데스티네이션 정보 저장
◦
파이프라인 실행 기록 및 통계 수집
◦
스키마 레지스트리 역할
◦
크롤러: 신규 테이블·파일 자동 인식 후 메타데이터 등록
•
제약
◦
Glue ETL 컴포넌트의 일부로, 독립적 아키텍처 아님
7.5.2 오픈소스
DataHub
•
기능
◦
데이터 소스 위치·설명 관리
◦
최종 사용자 검색·탐색 UI 제공
•
단점
◦
문서화 미흡으로 초기 도입 진입장벽
◦
추가 인프라 구축 필요